Hace tiempo que quería tener mi primer contacto con Docker. Sabía, conceptualmente y muy básicamente de que trata, es decir, que es una especie de virtualización: en la cual contamos con “imágenes” que tienen lo estrictamente necesario para que, por ejemplo, una aplicación web se ejecute independiente del sistema operativo y sus particulares condiciones. Con una una imagen creada ésta debería ejecutarse en un “contenedor” exactamente igual en mi máquina de desarrollador como en el ambiente de pruebas o en producción (en realidad en cualquier escenario), inclusive si estos ambientes están en la nube.
Entonces, aterrizando un poco más los conceptos: una imagen en Docker esta compuesta, por capas donde la primera capa seria una especie de sistema operativo mínimo (con lo mínimo requerido para lo que sea que vayamos a crear o utilizar se ejecute correcta y eficientemente), otras capas serian componentes esenciales para nuestro propósito (en el ejemplo de una aplicación web, es necesario un servidor web), configuraciones, variables de ambiente o entorno, y encima de estas capas estarían los archivos necesarios para que nuestra aplicación se ejecute. Algo muy importante a tomar en cuenta es que las imágenes son inmutables, o sea, una vez creadas, no cambian o se alteran.
Un contenedor de Docker, es la ejecución de una imagen, y éste si es modificable, sin embargo, una vez eliminado el contenedor todo lo que no sea parte de la imagen se perderá. Es decir, si tenemos una aplicación que guarda archivos dentro de su contenedor, cada vez que creemos un contenedor a partir de su imagen siempre se comportará de la misma manera, y podremos “subir” archivos, pero una vez eliminado el contenedor todos los archivos “subidos” se perderán.
Ahora bien ¿Qué necesitamos para comenzar a utilizar Docker en un ambiente de desarrollo basado en Windows? Necesitaríamos el Docker Desktop el cual lo podemos encontrar en este Link. Una vez instalado tendremos un icono como este (la imagen incluye la configuración por defecto al instalar el Docker Desktop).
Como se mencionó, en la imagen anterior vemos la configuración por defecto. El aspecto más importante aquí (según yo) es la que dice “Use the WSL 2 based engine” esto significa que Docker utilizará el motor basado en el “Windows Subsystem for Linux” siendo 2 la versión más reciente de este subsistema incluida dentro Windows 10. En teoría se podría usar Hyper-V, pero usar WSL es la manera más optima actualmente.
Ahora demos nuestros primeros pasos con Docker, nuestro objetivo es el siguiente: vamos a crear un mini sitio web a partir de cual crearemos una imagen Docker y luego la montaremos en un contenedor, todo utilizando VSCode.
Primero dentro de un folder (DockerTest en mi caso) creamos una carpeta llamada html y dentro de esta creamos un archivo llamado index.html con apenas código, quedando algo similar a lo siguiente:
Usando la extensión VSCode “Live Server” podemos hacer clic en el ícono de la barra inferior que dice “Go Live” y podemos ver el resultado de la ejecución de esta pequeña página html.
Obviamente esto se está ejecutando en un servidor de mi máquina, de momento no tiene nada que ver con Docker. Pero a eso vamos de inmediato. Primero necesitamos instalar la extensión de Docker para VSCode lo que nos dará intellisense para los archivos de configuración de Docker y alguna funcionalidad adicional.
Con esta herramienta ya instalada vamos a crear un archivo fuera de la carpeta html, es decir en el directorio raíz llamado dockerfile (sin ninguna extensión). De manera que se vea así:
En este dockerfile se va a definir como se crearán las imágenes que eventualmente se ejecutaran en contenedores para nuestro proyecto. Estos dockerfiles se componen de pasos. En este caso debemos definir los pasos para crear las diferentes capas que contendrá la imagen que eventualmente “servirá” la página html que acabamos de crear. ¿Cómo sabemos cómo crear un dockerfile para una necesidad en particular? Pues existe este sitio Explore Docker's Container Image Repository | Docker Hub por medio de cual podemos obtener los pasos requeridos para obtener los resultados deseados. Tiene una amplia colección por lo que deberíamos mantenerla a mano.
En mi caso deseo una imagen que me permita servir páginas html, por lo que elegiré httpd que permite crear una imagen de un servidor apache
En la misma página más abajo (es importante leer toda la documentación) hace mención de la variante Alpine la cual se basa en la distribución de Linux Alpine la cual es muy pequeña. Por lo cual es la que vamos a usar. El contenido de nuestro dockerfile quedaría entonces de la siguiente manera:
Obviamente en un dockerfile se puede definir muchas cosas más, pueden ser bastante largos. Para nuestro pequeño experimento este par de líneas son suficientes. La primer línea define el tipo de imagen que queremos: un servidor apache basado en Linux Alpine y con la segunda línea copiamos nuestros archivos a la estructura donde el servidor apache de la imagen los va a necesitar.
Una vez con este dockerfile creado podemos empezar nuestra aventura con docker. Abrimos una terminal dentro de VS Code y podemos empezar a jugar con los comandos. Por ejemplo, “docker images” nos mostrará las imágenes que tenemos en nuestro Docker Engine, si lo ejecutamos nos indicará que ahora mismo no tenemos ninguna imagen creada
Usando el siguiente comando creamos nuestra primera imagen “docker build -t docker-test:1.0.0 .”. Estamos usando el comando build con el parámetro -t para darle nombre a la imagen, en este ejemplo docker-test, lo que esta después de los dos puntos es un tag. Es importante notar que se debe colocar un punto al final antes del cual hay un espacio, ese espacio adicional es de olvido frecuente. Además, este comando se debe ejecutar en la carpeta donde se encuentra nuestro dockerfile.
Ahora, si de nuevo ejecutamos el comando “docker images” veremos la imagen recién creada
Las primeras dos columnas corresponden con los parámetros del comando build. La columna Image Id, nos sirve como identificador único de la imagen. Por ejemplo, si quisiéramos saber como se conformó esta imagen podemos utilizar el comando “docker image history ed1” donde ed1 son los primeros tres caracteres de la image id (hay que usar suficientes caracteres para una única e inequívoca identificación)

Podemos decir que esta lista corresponde a las diferentes capas de nuestra imagen donde la entrada más inferior (5.6 MB) corresponde al sistema operativo, la entrada de 49.2 MB corresponde al servidor web, y la entrada superior (181 B) corresponde a nuestra pagina html. Es muy importante notar la palabra “missing” en la columna Image, quiere decir que todos esos archivos están dentro de nuestro Docker Engine, es decir, se crean una única vez dentro del gestor, por lo que si se crea una segunda imagen estos paquetes ya existen y no es necesario bajarlos nuevamente; también significa que si creamos un contenedor este usará estos archivos y al crear un segundo contenedor éste re-usará los mismos archivos por lo que estaríamos ahorrando mucho espacio.
Bueno, ya tenemos nuestra imagen, ahora ¿Qué sigue? Pues bien, como se mencionó anteriormente las imágenes son “read only”, lo que sigue es ejecutar esta imagen a través de un contenedor. Para esto ejecutamos el siguiente comando “docker run --name contenedor01 -p 8080:80 docker-test:1.0.0”. Para explicar un poco el comando diré que luego del parámetro --name va el nombre que le daremos a nuestro contenedor (contenedor01), seguidamente, como en este caso estamos usando una imagen que tiene un servidor web, definimos el parámetro -p que es para mapear puertos entre el contenedor y el de la maquina host (mi maquina), a la izquierda de los dos puntos va el puerto local de mi maquina (8080) y a la derecha para el puerto al que corresponde dentro del contenedor (80) y finalmente se debe proporcionar el nombre y el tag de la imagen que vamos a ejecutar (docker-test:1.0.0)

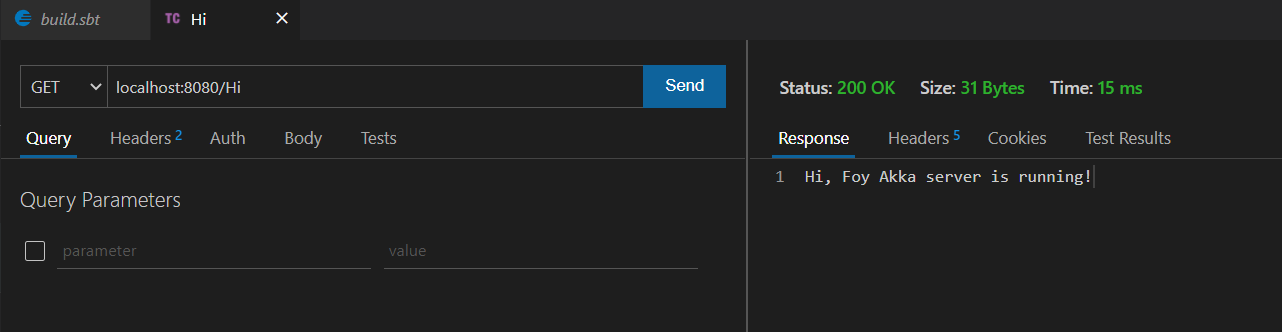
Si en este punto vamos a nuestro navegador y usamos la ruta localhost:8080 deberíamos ver que nuestro contenedor esta sirviendo la página html que habíamos creado
¡Y aquí lo tenemos, nuestro primer contenedor Docker funcionando como se debe!
Podemos listar los contenedores que tenemos en nuestro gestor utilizando el comando “docker ps -all” (si usamos “docker ps” únicamente nos listará los contenedores que se estén ejecutando)
Tal y como se aprecia en la imagen, tenemos un container id que nos sirve para referenciar el contenedor. De esta manera podemos usar el comando “docker stop b14” para detener la ejecución del contenedor, donde b14 corresponden a los primeros caracteres del container id.
Si intentamos de nuevo la ruta locahost:8080, ésta ya no estará disponible porque el contenedor está detenido.
Para volver a iniciar el contenedor podemos usar el comando “docker start b14” con lo que el contenedor volverá a iniciar su ejecución y la página de nuevo estará disponible.
Ahora realicemos algunos ajustes y añadidos a nuestro sitio web. Primero ajustemos la palabra “imágenes” de manera que utilicemos el código html de la letra acentuada, además voy a añadir una segunda página que se puede llamar desde la primera y viceversa quedando más o menos así:
Ahora, sin tocar nuestro dockerfile, hagamos una segunda imagen de esta nueva versión de nuestro mini sitio web, utilizando el siguiente comando imagen “docker build -t docker-test:1.0.1 .”
Como podemos constatar, la única diferencia con respecto a la primera vez que ejecutamos este comando es que cambiamos el tag de 1.0.0 a 1.0.1. Si ejecutamos de nuevo el comando “docker images” corroboraremos que ahora tenemos dos imágenes:
Ahora crearé un segundo contenedor basado en esta segunda imagen por medio del siguiente comando “docker run --name contenedor02 -p 8081:80 docker-test:1.0.1” de manera que en mi maquina se utilice el puerto 8081 para acceder a este segundo contenedor.
Ahora con el comando “docker ps -a” podemos verificar el numero de contenedores que tenemos creados:
Aquí podemos verificar que nuestro contenedor02 se está ejecutando pero el contenedor01 no, por lo procedemos a iniciarlo usando el comando “docker start b14” y seguidamente probamos ambas direcciones:
localhost:8080
localhost:8081
Cómo se ve, en la segunda versión se ajustó correctamente la letra acentuada y se añadió más funcionalidad, sin embargo, podemos ejecutar aun la primera versión, al mismo tiempo, inclusive, que la segunda y compararlas. Esto nos puede ayudar con varias tareas propias del desarrollo.
Finalmente, para terminar estos primeros pasos voy a limpiar todo.
Para detener los contenedores utilizo el comando “docker stop b14” y “docker stop d57” y para borrar ambos contenedores el comando “docker rm b14” y docker rmd57” y ejecutamos el comando “docker ps -a” para verificar que ya no contamos con ningún contenedor. (hay una forma más eficiente de realizar esta tarea que incluyo al final de la entrada)
Ahora si deseamos eliminar las imágenes utilizamos el comando “docker rmi 56e” y “docker rmi ed1” y ejecutamos el comando “docker images” para verificar que no queda ninguna imagen:
Notas, recapitulación y recomendación
Hasta aquí todo lo hemos hecho a punta de comandos en la terminal, pero es importante también saber que el Docker Desktop tiene una interfaz gráfica que nos ayuda a gestionar imágenes y contenedores. Por ejemplo, listar los contenedores que tenemos y desde aquí ejecutarlos, detenerlos o borrarlos
Ver la interacción de un contenedor en ejecución
O listar las imágenes y a partir de ellas crear el contenedor
En esta ultima imagen un detalle importante a notar es la etiqueta Total size. A pesar de contar con dos imágenes ambas con 54.52 MB, nos indica que el tamaño total es de 54.52 MB, no el doble, esto es, como se mencionó anteriormente, porque ambas imágenes comparten la mayoría de capas.
Resumen de comandos básicos de Docker:
Uso
|
Comando
|
Comentario
|
|
Listar imágenes
|
docker images
|
|
|
Listar Contenedores
|
docker ps -a
|
Sin el parámetro -a
(-all) se listan solo los contenedores en ejecución
|
|
Crear imagen
|
docker build -t <nombre:tag> .
|
Se debe estar en una
carpeta que contenga el dockerfile a partir del cual se crea la imagen. No olvidar
espacio y punto final
|
|
Historia de imagen
|
docker image history
<imageID>
|
|
|
Crear contenedor
|
docker run --name <nombreContenedor>
-p <puertoLocal:puertoContenedor> <nombreImagen:tag>
|
En este caso se usa
el parámetro -p por ser una imagen de servidor web
|
|
Iniciar contenedor
|
docker start <containerID>
|
|
|
Detener contenedor
|
docker stop <containerID>
|
|
|
Eliminar contendor
|
docker rm <containerID>
|
Se pueden borrar varios
con un solo comando separando los ids por un espacio.
|
|
Eliminar imagen
|
docker rmi <imageID>
|
Se pueden borrar varias
con un solo comando separando los ids por un espacio. Se puede usar -f como parámetro
adicional para forzar la eliminación
|
Recordar que no es necesario escribir todo el Image ID o Container ID basta con los primeros caracteres siempre que permitan una única e inequívoca identificación (de hecho, es posible solo usar el primer carácter si no tenemos muchos ítems en nuestros repositorios)
Una última recomendación
Todos los comandos que se utilizaron en este post se introdujeron en una terminal tipo bash, pero se puede usar una terminal powershell que puede ser preferible dada la flexibilidad de uso. Por ejemplo, podríamos tener lo siguiente

Son dos imágenes y dos contenedores ejecutándose y queremos detener y eliminar todos los contenedores e imágenes. Como ya vimos, para hacerlo tradicionalmente necesitamos los containers id e images id, sin embargo, con powershell podríamos usar el siguiente comando para detener todos los contenedores en ejecución “docker stop $(docker ps -q)” (docker ps -q devuelve solo los containers id de los contenedores en ejecución). Seguidamente podemos usar “docker rm $(docker ps -a -q)” (como habrán intuido docker ps -a -q devuelve los containers id de todos contenedores aun cuando no se estén ejecutando) y finalmente para borrar todas las imágenes ejecutaríamos el siguiente comando “docker rmi $(docker images -q)” (efectivamente, docker images -q devuelve los images id de todas las imágenes)
El uso de pawershell nos podría hacer la vida más sencilla cuando utilizamos Docker.
El mundo de Docker es muy amplio, esta entrada es apenas una mínima introducción a partir de la cual podemos seguir explorando qué otras cosas podemos hacer, qué otros beneficios podemos obtener del uso de Docker en nuestros desarrollos.