En nuestro quehacer diario hay pequeñas tareas que nos quitan alguna cantidad de tiempo. A veces nos acostumbramos a hacer estas tareas de una manera casi autómata sin preguntarnos ¿Será que hay una forma más eficiente de hacer esto?
Un ejemplo concreto mío. Estando desarrollando una aplicación web de tamaño medio, tenia que estar buscando páginas en la solución y lo hacía usando Ctrl+Shift+f y colocando el nombre del archivo a buscar. Esto en mi máquina se realizaba relativamente rápido, pero cuando me tocó hacer la misma tarea en una máquina de menos recursos la cosa se estancó.
Pues resulta que existe el comando Ctrl+[Comma], que es la ventana de "navegar a", la cual busca directamente los archivos, no en los archivos como hace el shortcut que usaba antes. simple y llanamente la forma correcta y eficiente de como debía hacerlo.
La lista completa de los atajos, shortcuts de Visual Studio 2013 esta aquí tal ves sirva para que, de vez en cuando, le echemos una mirada para ver si no hay tareas con atajos más eficientes.
16 nov 2013
12 may 2013
Concatenar varios registros en una sola columna
Supongamos que, en SQL Server, tenemos una tabla de proveedores y una tabla aparte donde se almacenan los números de teléfonos de dichos proveedores como registros separados. De modo que tendríamos algo similar a lo siguiente:
Proveedor:
ProveedorTelefono:
Supongamos que una de las necesidades de nuestro cliente es que mostremos, en un grid o tabla, cada proveedor con todos sus teléfonos en una sola columna separados por comas.
Como para con casi todo en la vida, hay varias formas de hacerlo; podríamos traernos todo en dos consultas separadas (o en una sola por medio de joins, con la información de los proveedores repetida) y ya en nuestra aplicación, por medio de un bucle, concatenar los teléfonos en un solo campo, o usar un store procedure con un cursor y hacer mas o menos lo mismo que en el punto anterior pero en el motor de base de datos o tantas otras aproximaciones.
También se puede utilizar la combinación de una función y una consulta de la siguiente manera:
Primero creamos una función para devolver los teléfonos concatenados por proveedor:
Finalmente utilizamos nuestra función dentro de nuestra consulta:
Y ya con esto concatenamos varios registros en una sola columna...y es fácil de traducir a otros motores de base de datos.
Proveedor:
| codProveedor | desRazonSocial | ... |
| 1 | Proveedor de Prueba 1 | ... |
| 2 | Proveedor de Prueba 2 | .. |
ProveedorTelefono:
| codProveedor | desTelefono |
| 1 | 88881685 |
| 1 | 89000000 |
| 1 | 98012012 |
| 2 | 78912000 |
| 2 | 12345678 |
Supongamos que una de las necesidades de nuestro cliente es que mostremos, en un grid o tabla, cada proveedor con todos sus teléfonos en una sola columna separados por comas.
Como para con casi todo en la vida, hay varias formas de hacerlo; podríamos traernos todo en dos consultas separadas (o en una sola por medio de joins, con la información de los proveedores repetida) y ya en nuestra aplicación, por medio de un bucle, concatenar los teléfonos en un solo campo, o usar un store procedure con un cursor y hacer mas o menos lo mismo que en el punto anterior pero en el motor de base de datos o tantas otras aproximaciones.
También se puede utilizar la combinación de una función y una consulta de la siguiente manera:
Primero creamos una función para devolver los teléfonos concatenados por proveedor:
CREATE FUNCTION [dbo].[fnTelefonosProveedor] (@codProveedor int)
RETURNS varchar(600)
AS
BEGIN
DECLARE @listaTelefonos varchar(600)
SET @listaTelefonos = null
SELECT @listaTelefonos = COALESCE(@listaTelefonos, '') +
CASE
WHEN @listaTelefonos IS NULL THEN ''
ELSE
', '
END
+ T.desTelefono
FROM ProveedorTelefono T
WHERE T.codProveedor = @codProveedor
RETURN @listaTelefonos
END
Finalmente utilizamos nuestra función dentro de nuestra consulta:
SELECT P.conCodigoProveedor, P.nomRazonSocial,
dbo.fnTelefonosProveedor(P.codProveedor) AS desTelefonos
FROM Proveedor P
| codProveedor | desRazonSocial | desTelefonos |
| 1 | Proveedor de Prueba 1 | 88881685, 89000000, 98012012 |
| 2 | Proveedor de Prueba 2 | 78912000, 12345678 |
Y ya con esto concatenamos varios registros en una sola columna...y es fácil de traducir a otros motores de base de datos.
1 may 2013
Count Incorrecto
Alguna que otra ves encontramos comportamientos extraños en algunas aplicaciones. A veces es un poco de desconocimiento, en otras malas prácticas y en otras algo de ambas.




Me encontré una aplicación en que en una de sus características simplemente debía retornar la cantidad de registros dado un campo de la tabla como filtro. Y el dato devuelto estaba erróneo. ¿Cómo algo tan simple y básico puede estar equivocado?
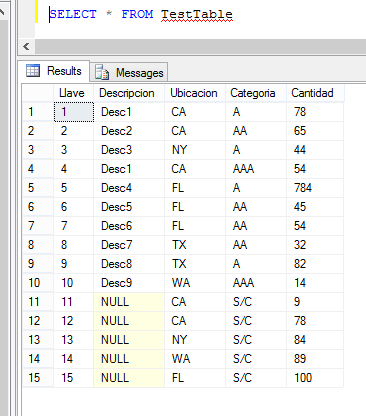
Veamos un ejemplo: supongamos que tengo una Tabla con los siguientes registros:
Ahora realicemos un simple count(*) de los registros cuya Ubicacion sea 'CA'.

Cinco registros, esto es correcto. Pero todos sabemos que no es una buena práctica utilizar el asterisco(*) en una consulta por lo ineficiente que resulta la resolución de la misma. Entonces elegimos un campo para realizar el mismo count, digamos Descripcion.
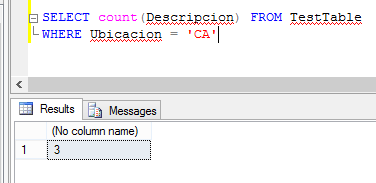
Y el resultado es... erróneo.
¿Por qué? Simplemente por que la implementación del count excluye de la cuenta los valores nulos resultantes de evaluar la expresión que estemos usando como parámetro para cada columna resultante del filtro. Así bien, existen dos registros con Ubicación 'CA' cuya Descripcion (la expresión a evaluar) es null y éstos no son tomados en cuenta en el resultado.
La solución es simple, utilicemos una columna en el que no haya posibilidad de valores nulos. En este particular el campo llave. O También podemos usar una expresión, por ejemplo 1, la cual evaluada por cada columna siempre será distinta de null.

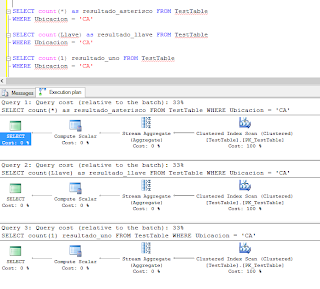
Una ultima reflexión si somos un poco más inquisitivos y nos preguntamos ¿Cual de las tres sentencias que arrojan el resultado correcto es la más óptima? Podemos referirnos al plan de ejecución de cada sentencia.

Como podemos notar los tres planes de ejecución son exactamente iguales, entonces, podemos decir que las tres sentencias son equivalentes, por lo que, en este caso en particular, el usar el count(*) no significa mayor perdida de eficiencia de la consulta.
En lo personal prefiero el count(1) ya que no queda sujeta a ninguna columna de la tabla y su evaluación no depende de la implementación del motor de la base de datos.
14 abr 2013
Formateo condicional en Reporting Services
Reporting services tiene una característica muy potente: las expresiones. Son aplicables a casi todo y para ilustrar ligeramente las ventajas de uso utilizaremos el reporte que creamos en nuestro post anterior.
Utilizaremos una técnica que inglés se conoce"conditional formatting" o en simple y plano español formateo condicional. Consiste en cambiar el comportamiento de las propiedades que le dan formato al reporte o a sus componentes, filas, campos, encabezados, etc. de una otra forma dependiendo de alguna condición.
Nuestro reporte mencionado anteriormente consistía en un listado de productos y su inventario agrupado por bodega.

Ahora supongamos que necesitamos que si el inventario de un producto está por debajo de 50 la cantidad del mismo debe aparecer en rojo, de lo contrario que se mantenga en negro.
Comencemos. Abrimos nuestra solución de reportes en Visual Studio 2008 (El único IDE que soporta Reporting Services 2008), seleccionamos nuestro reporte el cual nos aparecerá en modo diseño. Aquí hacemos clic derecho sobre el campo que deseamos formatear y elegimos del menú emergente la opción "Placeholder Properties..."

Se nos abrirá una pantalla en la que seleccionaremos la opción Font del panel de la izquierda.
Seguidamente hacemos clic en el Boton ƒx al lado del casilla de Color. Se nos presentará la pantalla para crear expresiones, En ésta podemos usar una expresión como la siguiente para lograr el efecto deseado.

Damos dos veces OK, y nos vamos a la cejilla Preview de nuestro reporte para ver como queda nuestro formateo:

Bien. Y que pasa si nos dicen que mejor sería que las cantidades en cero aparezcan en rojo, los menores a 50 amarillo y los mayores o iguales a 50 en verde. El procedimiento es el mismo solo que la expresion a utilizar sería algo como esto:

Es interesante notar que, como mencioné al principio, este tipo de expresiones se pueden usar en muchas de las propiedades de los diferentes elementos del reporte.
Utilizaremos una técnica que inglés se conoce"conditional formatting" o en simple y plano español formateo condicional. Consiste en cambiar el comportamiento de las propiedades que le dan formato al reporte o a sus componentes, filas, campos, encabezados, etc. de una otra forma dependiendo de alguna condición.
Nuestro reporte mencionado anteriormente consistía en un listado de productos y su inventario agrupado por bodega.

Comencemos. Abrimos nuestra solución de reportes en Visual Studio 2008 (El único IDE que soporta Reporting Services 2008), seleccionamos nuestro reporte el cual nos aparecerá en modo diseño. Aquí hacemos clic derecho sobre el campo que deseamos formatear y elegimos del menú emergente la opción "Placeholder Properties..."


=Iif(Fields!Stock.Value < 50, "Red", "Black")

Damos dos veces OK, y nos vamos a la cejilla Preview de nuestro reporte para ver como queda nuestro formateo:

Bien. Y que pasa si nos dicen que mejor sería que las cantidades en cero aparezcan en rojo, los menores a 50 amarillo y los mayores o iguales a 50 en verde. El procedimiento es el mismo solo que la expresion a utilizar sería algo como esto:
=Switch(fields!Stock.Value = 0,"Red", fields!Stock.Value < 50, "Gold", fields!Stock.Value >= 50, "Green")

Es interesante notar que, como mencioné al principio, este tipo de expresiones se pueden usar en muchas de las propiedades de los diferentes elementos del reporte.
30 mar 2013
Añadiendo un Reporte al Servidor de Reportes Manualmente
Vamos a añadir un reporte sencillo a nuestro servidor de Reportes de forma manual en un servidor de Reporting Servces 2008. La idea es crear un reporte de productos en inventario por bodega y subirlo de forma totalmente manual a nuestro servidor de reportes. Las tablas de donde se están tomando los datos ya están creadas en una base de datos de pruebas, con el fin de concentrarnos únicamente en la creación y subida del reporte.
Primero crearemos nuestro reporte; para esto utilizaremos Visual Studio 2008 que es en el que podemos trabajar los reportes para SQL Server 2008.
Primeramente creamos un nuevo proyecto tipo “Business Intelligence Projects” y dentro de este tipo elegimos la plantilla “Report Server Project”

A continuación se nos mostrará la estructura generada para nuestra solución: una carpeta donde crear los reportes y otra donde crea los orígenes de datos (nuestras conexiones al backend de donde sacaremos los datos para nuestros reportes).
Primero creamos nuestra conexión a nuestra base de datos, hacemos clic derecho sobre la carpeta Shared Data Sources y en el menú auxiliar seleccionamos la opción Add New Data Source.

En la pantalla que se nos abre se nos permite editar las propiedades de nuestra conexión.
 Elegimos un nombre adecuado para nuestro origen de datos y a continuación clic en “Edit…” para editar nuestro string de conexión.
Elegimos un nombre adecuado para nuestro origen de datos y a continuación clic en “Edit…” para editar nuestro string de conexión.

Colocamos los datos que se nos solicitan, probamos la conexión para verificar que todo está en orden y le damos OK. Volvemos a la pantalla anterior donde vemos nuestro string de conexión ya formada y le damos OK.
Ya contamos con nuestro origen de datos disponible, ahora vamos a crear nuestro sencillo reporte de prueba. Primero hacemos clic derecho sobre la carpeta “Reports” y elegimos la opción “Add New Report” del menú emergente.

Se nos presentará una pantalla de inicio de un wizard en la que podremos ir construyendo nuestro reporte. Hacemos clic en next en la pantalla de presentación del wizard. La siguiente pantalla que se nos mostrará es en la que podemos elegir o crear nuestro origen de datos.

Como ya lo teníamos creado de previo, simplemente le damos clic en Next. Pasamos a la pantalla, que es en la que diseñamos la consulta que vamos a realizar

Tenemos dos opciones: podemos escribir la consulta en el espacio “Query string” o podemos usar el botón “Query Builder…” para acceder a un diseñador gráfico de consultas.
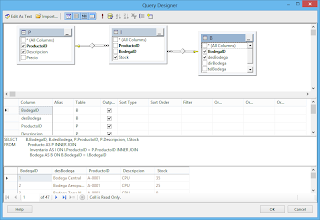
La consulta que voy a utilizar extrae el id de la bodega, el nombre de la bodega, el id del producto, la descripción del producto y la cantidad en stock.
Independiente del camino elegido, una vez definida la consulta le damos clic en Next (primero en Ok si estamos en el query builder) para continuar con el proceso. Entramos en la etapa de diseñar la presentación de los datos de nuestro sencillo reporte. Primero Elegimos si nuestro reporte será tabular o matricial.

Yo lo voy a dejar Tabular y clic en Next. Seguidamente pasamos a la distribución de los campos en la tabla

Los campos que coloquemos en la sección Page quedaran como encabezado de página, los que coloquemos en Group formarán los agrupamientos y los que dejemos en Details, pues serán las componentes de las líneas del detalle del reporte. Así de esta manera, la distribución me quedó de la siguiente forma.
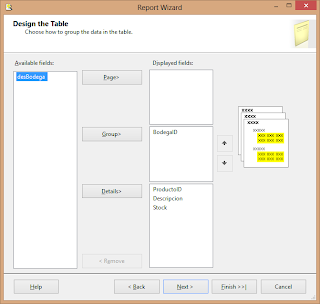
Nótese que agrupé por el Id de bodega pero deje fuera la descripción de la bodega. Esto es porque si los añado ahora en el group se me generan dos agrupaciones: una para el id de bodega y otro para la descripción de la bodega, y este no es el efecto que estoy buscando.
Hacemos clic en Next, lo que nos permite, en la siguiente pantalla escoger el “layout” de nuestro reporte así como si queremos incluir subtotales o añadir la característica de poder ocultar/mostrar los detalles por agrupamiento (drilldown).

Yo lo voy a dejar como esta por defecto y clic en Next. Ahora pasamos a elegir los aspectos de estilo de nuestro reporte.

Escogemos en el mejor nos parezca y hacemos clic en Next. Llegamos a la pantalla final. Elegimos un nombre apropiado para nuestro reporte y hacemos clic en Finish.

Hemos acabado con la definición y estilo de nuestro reporte, si le damos preview en este momento se nos mostrará algo como asi

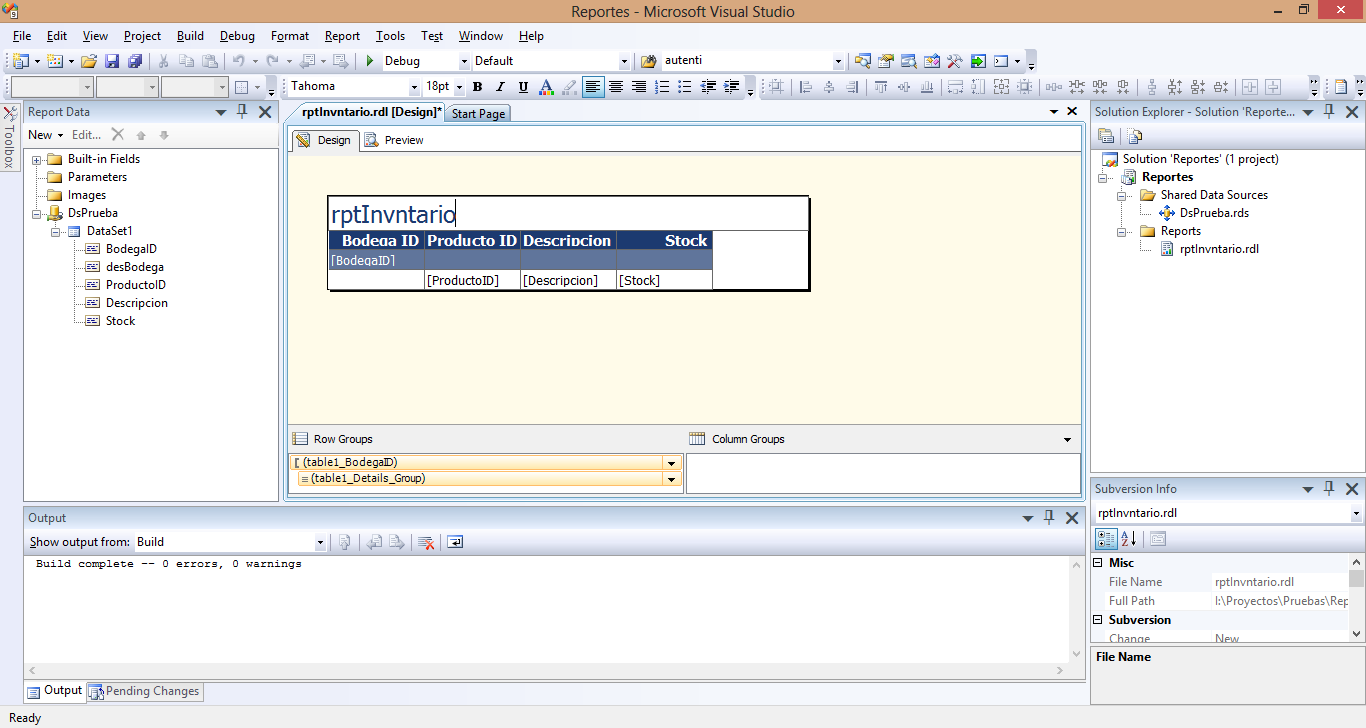
Vamos a ajustarlo para que nos quede mejor. Primero nos devolvemos a la cejilla de diseño (Design)
 Empecemos por cambiar en el encabezado, modificando la etiqueta rptInventario por “Inventario por Bodega”. Añadimos la descripción de la bodega a nuestro encabezado de grupo, para esto hacemos clic dentro de la segunda celda de nuestro encabezado de grupo y clic sobre el icono que aparece al lado derecho de la misma
Empecemos por cambiar en el encabezado, modificando la etiqueta rptInventario por “Inventario por Bodega”. Añadimos la descripción de la bodega a nuestro encabezado de grupo, para esto hacemos clic dentro de la segunda celda de nuestro encabezado de grupo y clic sobre el icono que aparece al lado derecho de la misma
 Elegimos el campo que contiene la descripción de la bodega (desBodega). Como el espacio es pequeño para la descripción de la misma seleccionamos adicionalmente la celda contigua a la derecha, hacemos clic derecho y seleccionamos “Merge Cells” del menú emergente. Acomodamos un poco el espacio procurando que los datos queden de la mejor manera. El resultado final sería algo como esto:
Elegimos el campo que contiene la descripción de la bodega (desBodega). Como el espacio es pequeño para la descripción de la misma seleccionamos adicionalmente la celda contigua a la derecha, hacemos clic derecho y seleccionamos “Merge Cells” del menú emergente. Acomodamos un poco el espacio procurando que los datos queden de la mejor manera. El resultado final sería algo como esto:

Ahora a subirlo al servidor de reportes.
Primero debemos acceder a nuestro servidor de reportes por medio del browser. En mi caso la dirección es http://foypc/Reports_FOYSERVER/Pages/Folder.aspx.

Añadimos una nueva carpeta donde poner nuestro reporte:

Una vez en nuestra nueva carpeta utilizamos el botón Upload file, para subir nuestro reporte

Creamos un nuevo origen de datos usando el botón “New Data Source”. Llenamos la información que se nos solicita:

Y hacemos clic en OK. Seguidamente hacemos clic sobre nuestro reporte. Nos parecerá una pantalla como la siguiente:

Hacemos clic en la pestaña Properties y luego en Data Sources del panel de la izquierda.

Hacemos clic en el botón Browse, para buscar nuestro datasourse recién creado:

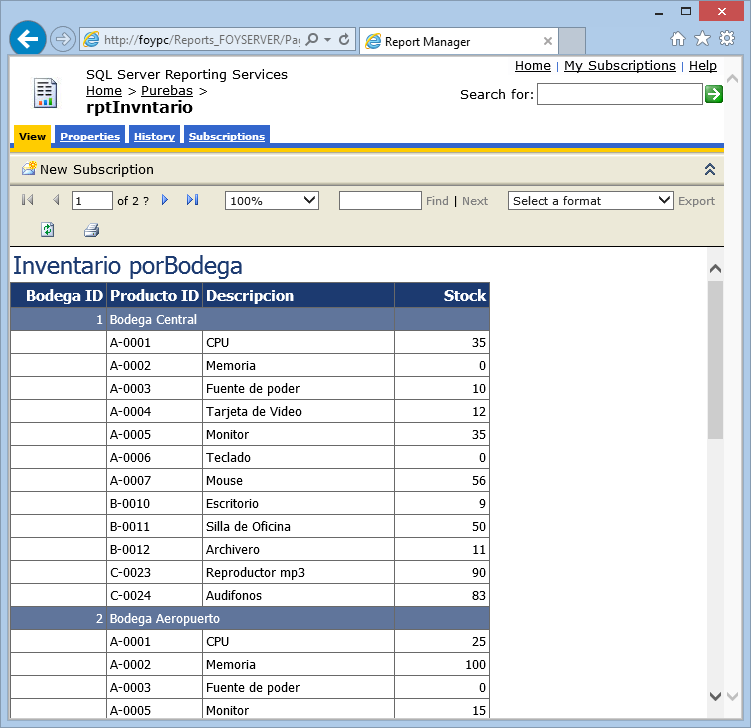
Hacemos clic en OK y luego en Apply para dejar en firme nuestros cambios. Ahora finalmente damos clic en la pestaña View para ver que nuestro reporte ya es completamente funcional.

¡Listo! Con esto finalizo este pequeño tutorial.
Primero crearemos nuestro reporte; para esto utilizaremos Visual Studio 2008 que es en el que podemos trabajar los reportes para SQL Server 2008.
Primeramente creamos un nuevo proyecto tipo “Business Intelligence Projects” y dentro de este tipo elegimos la plantilla “Report Server Project”

A continuación se nos mostrará la estructura generada para nuestra solución: una carpeta donde crear los reportes y otra donde crea los orígenes de datos (nuestras conexiones al backend de donde sacaremos los datos para nuestros reportes).
Primero creamos nuestra conexión a nuestra base de datos, hacemos clic derecho sobre la carpeta Shared Data Sources y en el menú auxiliar seleccionamos la opción Add New Data Source.

En la pantalla que se nos abre se nos permite editar las propiedades de nuestra conexión.


Colocamos los datos que se nos solicitan, probamos la conexión para verificar que todo está en orden y le damos OK. Volvemos a la pantalla anterior donde vemos nuestro string de conexión ya formada y le damos OK.
Ya contamos con nuestro origen de datos disponible, ahora vamos a crear nuestro sencillo reporte de prueba. Primero hacemos clic derecho sobre la carpeta “Reports” y elegimos la opción “Add New Report” del menú emergente.

Se nos presentará una pantalla de inicio de un wizard en la que podremos ir construyendo nuestro reporte. Hacemos clic en next en la pantalla de presentación del wizard. La siguiente pantalla que se nos mostrará es en la que podemos elegir o crear nuestro origen de datos.

Como ya lo teníamos creado de previo, simplemente le damos clic en Next. Pasamos a la pantalla, que es en la que diseñamos la consulta que vamos a realizar

Tenemos dos opciones: podemos escribir la consulta en el espacio “Query string” o podemos usar el botón “Query Builder…” para acceder a un diseñador gráfico de consultas.

La consulta que voy a utilizar extrae el id de la bodega, el nombre de la bodega, el id del producto, la descripción del producto y la cantidad en stock.
Independiente del camino elegido, una vez definida la consulta le damos clic en Next (primero en Ok si estamos en el query builder) para continuar con el proceso. Entramos en la etapa de diseñar la presentación de los datos de nuestro sencillo reporte. Primero Elegimos si nuestro reporte será tabular o matricial.

Yo lo voy a dejar Tabular y clic en Next. Seguidamente pasamos a la distribución de los campos en la tabla

Los campos que coloquemos en la sección Page quedaran como encabezado de página, los que coloquemos en Group formarán los agrupamientos y los que dejemos en Details, pues serán las componentes de las líneas del detalle del reporte. Así de esta manera, la distribución me quedó de la siguiente forma.

Nótese que agrupé por el Id de bodega pero deje fuera la descripción de la bodega. Esto es porque si los añado ahora en el group se me generan dos agrupaciones: una para el id de bodega y otro para la descripción de la bodega, y este no es el efecto que estoy buscando.
Hacemos clic en Next, lo que nos permite, en la siguiente pantalla escoger el “layout” de nuestro reporte así como si queremos incluir subtotales o añadir la característica de poder ocultar/mostrar los detalles por agrupamiento (drilldown).

Yo lo voy a dejar como esta por defecto y clic en Next. Ahora pasamos a elegir los aspectos de estilo de nuestro reporte.

Escogemos en el mejor nos parezca y hacemos clic en Next. Llegamos a la pantalla final. Elegimos un nombre apropiado para nuestro reporte y hacemos clic en Finish.

Hemos acabado con la definición y estilo de nuestro reporte, si le damos preview en este momento se nos mostrará algo como asi

Vamos a ajustarlo para que nos quede mejor. Primero nos devolvemos a la cejilla de diseño (Design)


Ahora a subirlo al servidor de reportes.
Primero debemos acceder a nuestro servidor de reportes por medio del browser. En mi caso la dirección es http://foypc/Reports_FOYSERVER/Pages/Folder.aspx.

Añadimos una nueva carpeta donde poner nuestro reporte:

Una vez en nuestra nueva carpeta utilizamos el botón Upload file, para subir nuestro reporte

Creamos un nuevo origen de datos usando el botón “New Data Source”. Llenamos la información que se nos solicita:

Y hacemos clic en OK. Seguidamente hacemos clic sobre nuestro reporte. Nos parecerá una pantalla como la siguiente:

Hacemos clic en la pestaña Properties y luego en Data Sources del panel de la izquierda.

Hacemos clic en el botón Browse, para buscar nuestro datasourse recién creado:

Hacemos clic en OK y luego en Apply para dejar en firme nuestros cambios. Ahora finalmente damos clic en la pestaña View para ver que nuestro reporte ya es completamente funcional.
¡Listo! Con esto finalizo este pequeño tutorial.
2 mar 2013
Report server: User does not have required permissions
Se me presentó un error tratando de acceder mi propio servidor de reportes (http://foypc/Reports_FOYSERVER/Pages/Folder.aspx):


Como se puede ver el asunto es cuestión de permisos, lo curioso es que mi usuario es administrador de mi máquina, lo que me confundió bastante. Ya sobreponiéndome a esa primera sensación (frustración) y luego de investigar un poco hallé la siguiente solución:
Ejecutar el Internet Explorer como Administrador (en Windows 8 clic derecho sobre el icono y escoger “Run as administrator” en el menú inferior)

Una vez hecho esto y navegando a la ruta del servidor de reportes ya tenemos acceso.
 Estando en esta pantalla, nos vamos a la cejilla de “Properties” y dentro de esta a “Security”.
Estando en esta pantalla, nos vamos a la cejilla de “Properties” y dentro de esta a “Security”.




Ejecutar el Internet Explorer como Administrador (en Windows 8 clic derecho sobre el icono y escoger “Run as administrator” en el menú inferior)

Una vez hecho esto y navegando a la ruta del servidor de reportes ya tenemos acceso.


En esta pantalla añadimos nuestro usuario, en mi caso Roy, seleccionado todos los roles que creamos convenientes.

Le damos Ok y en la siguiente pantalla confirmamos que nuestra asignación a roles ya esta lista.

Volvemos a intentar la ruta en un browser que no se esté
ejecutando como administrador para verificar que nuestro usuario ya cuenta con
los permisos necesarios.

Listo! Ya tenemos acceso a nuestro servidor de reportes.
2 feb 2013
Login Perdido
Es normal que cuando hacemos una restauración de una base de datos nuestros usuarios pierdan su login asignado. Para volverles a asignar el login basta con la siguiente instrucción.
Listo ya podemos conectarnos de nuevo!
ALTER USER [UsuarioSinLogin]
WITH LOGIN = [LoginAAsignar]
Listo ya podemos conectarnos de nuevo!
19 ene 2013
Create Table elegante
Talves sea la fuerza de la costumbre, pero siempre que me ponían a crear un tabla en sql server, primero creaba la estructura de la tabla, las columnas, a parte el primary key y luego las foreign keys.
Recientemente me he dado cuenta que se puede crear todo de una vez y queda elegante. veamos un ejemplo
Primeramente tenemos la declaración de la creación de la tabla OrdenDetalle y entre paréntesis la descripción completa de la misma. Declaramos el primer campo, conOrden, que es una llave foránea proveniente de la tabla OrdenEncabezado. Todo esto lo añadimos en la especificación de la columna por medio de un constraint para darle nombre a la FK. Cada especificación completa de columna se separa de la siguiente con una coma.
Seguidamente añadimos conOrdenDetalle que es un número consecutivo Identity, que comienza en uno y se incrementa automáticamente de uno en uno. Añadimos dos columnas más: desLinea (varchar) y numPrecio (money), la descripción de la línea y el precio de la misma respectivamente.
Seguidamente dos columna de seguimiento como son el usuario que ingresó la línea (usrIngreso) y la fecha de ingreso (fecIngreso), ambas con valores por defecto usando constraints con nombres descriptivos.
Finalmente creamos una constraint más, correspondiente a la llave primaria de la tabla, usando las columnas conOrden y conOrdenDetalle dejando explícitamente que esta llave no se puede duplicar (innecesario en realidad ya que la segunda parte de la llave es un identity).
A mi, en lo personal, me parece una forma más compacta y elegante, que manejarlo por separado.
Recientemente me he dado cuenta que se puede crear todo de una vez y queda elegante. veamos un ejemplo
CREATE TABLE dbo.OrdenDetalle
(
conOrden INT NOT NULL
CONSTRAINT OrdenEncabezado_OrdenDetalle_FK FOREIGN KEY
REFERENCES dbo.OrdenEncabezado(conOrden),
conOrdenDetalle INT NOT NULL IDENTITY (1,1),
desLinea VARCHAR(254) NOT NULL,
numPrecio MONEY NOT NULL,
usrIngreso VARCHAR(20) NOT NULL
CONSTRAINT DF_OrdenDetalle_usrIngreso DEFAULT (user_name()),
fecIngreso DATETIME NOT NULL
CONSTRAINT DF_OrdenDetalle_fecingreso DEFAULT (getdate()),
CONSTRAINT PK_OrdenDetalle
PRIMARY KEY CLUSTERED (conOrden, conOrdenDetalle)
WITH (IGNORE_DUP_KEY = OFF)
);
Primeramente tenemos la declaración de la creación de la tabla OrdenDetalle y entre paréntesis la descripción completa de la misma. Declaramos el primer campo, conOrden, que es una llave foránea proveniente de la tabla OrdenEncabezado. Todo esto lo añadimos en la especificación de la columna por medio de un constraint para darle nombre a la FK. Cada especificación completa de columna se separa de la siguiente con una coma.
Seguidamente añadimos conOrdenDetalle que es un número consecutivo Identity, que comienza en uno y se incrementa automáticamente de uno en uno. Añadimos dos columnas más: desLinea (varchar) y numPrecio (money), la descripción de la línea y el precio de la misma respectivamente.
Seguidamente dos columna de seguimiento como son el usuario que ingresó la línea (usrIngreso) y la fecha de ingreso (fecIngreso), ambas con valores por defecto usando constraints con nombres descriptivos.
Finalmente creamos una constraint más, correspondiente a la llave primaria de la tabla, usando las columnas conOrden y conOrdenDetalle dejando explícitamente que esta llave no se puede duplicar (innecesario en realidad ya que la segunda parte de la llave es un identity).
A mi, en lo personal, me parece una forma más compacta y elegante, que manejarlo por separado.
Suscribirse a:
Entradas (Atom)



